子集选取
向量、矩阵、数据框的索引
基础篇子集选取单独作一章,说明它确实很重要。
上一章讲对象、数据类型和数据结构等概念。为了方便理解,我这里打个比方, 对象就是我们在计算机里新建了存储空间,好比一个盒子, 我们可以往盒子里面装东西(赋值),可以查看里面的内容或者对里面的内容做计算(函数),也可以从盒子里取出部分东西(子集选取)。
子集选取,就是从盒子里取东西出来[^1]。
[^1]: 操控盒子里的东西,比如把糖果变大,这个过程叫函数.
向量
对于原子型向量,我们有至少四种选取子集的方法
x <- c(1.1, 2.2, 3.3, 4.4, 5.5)- 正整数: 指定向量元素中的位置
x[1]x[c(1, 3)]x[c(3, 1)]- 负整数:删除指定位置的元素
x[-2]x[c(-3, -4)]- 逻辑向量:将
TRUE对应位置的元素提取出来
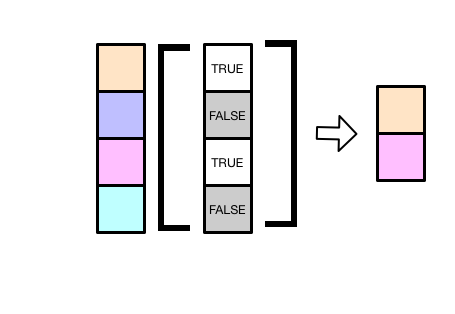
x[c(TRUE, FALSE, TRUE, FALSE, TRUE)]常用的一种情形;筛选出大于某个值的所有元素
x > 3x[x > 3]- 如果是命名向量
y <- c("a" = 11, "b" = 12, "c" = 13, "d" = 14)
y我们可以用命名向量,返回其对应位置的向量
y[c("d", "c", "a")]列表
对列表取子集,和向量的方法一样。向量的子集仍然是向量,使用[提取列表的子集,总是返回列表
l <- list(
"one" = c("a", "b", "c"),
"two" = c(1:5),
"three" = c(TRUE, FALSE)
)
l使用位置索引
l[1]也可以使用元素名
l["one"]如果想提取列表某个元素的值,需要使用 [[
l[[1]]也可以使用其中的元素名,比如[["one"]],
l[["one"]]取出one位置上的元素,需要写[["one"]],程序员觉得要写太多的字符了,太麻烦了,所以用$来简写
l$one所以请记住
[和[[的区别x$y是x[["y"]]的简写
矩阵
a <- matrix(1:9, nrow = 3)
a我们取第1行到第2行的2-3列,[1:2, 2:3],中间以逗号分隔,于是得到一个新的矩阵
a[1:2, 2:3]默认情况下, [ 会将获取的数据,以尽可能低的维度形式呈现。比如
a[1, 1:2]表示第1行的第1、2列,此时不是$1 \times 2$矩阵,而是包含了两个元素的向量。 以尽可能低的维度形式呈现,换句话说,这个[R表达式]长的像个矩阵,又有点像向量,向量的维度比矩阵低,那就是向量吧。
有些时候,我们想保留所有的行或者列,比如
- 行方向,只选取第 1 行到第 2 行
- 列方向,选取所有列
可以这样简写
a[1:2, ]对于下面这种情况,想想,会输出什么
a[, ]可以再简化点?
a[]是不是可以再简化点?
a数据框
数据框具有list和matrix的双重属性,因此
- 当选取数据框的某几列的时候,可以和list一样,指定元素位置索引,比如
df[1:2]选取前两列 - 也可以像矩阵一样,按照行和列的标识选取,比如
df[1:3, ]选取前三行的所有列
df <- data.frame(
x = 1:4,
y = 4:1,
z = c("a", "b", "c", "d")
)
dfLike a list
df[1:2]df[c("x", "z")]df[["x"]]df$xLike a matrix
df[, c("x", "z")]也可以通过行和列的位置
df[1:3, ]当遇到单行或单列的时候,也和矩阵一样,数据会降维
df[, "x"]如果想避免降维,需要多写一句话
df[, "x", drop = FALSE]这样输出的还是矩阵形式,但程序员总是偷懒的,有时候我们也容易忘记写drop = FALSE, 所以我比较喜欢下面的tibble.
增强型数据框
tibble是增强型的data.frame,选取tibble的行或者列,即使遇到单行或者单列的时候,数据也不会降维,总是返回tibble,即仍然是数据框的形式。
tb <- tibble::tibble(
x = 1:4,
y = 4:1,
z = c("a", "b", "c", "d")
)
tbtb["x"]tb[, "x"]除此以外,tibble还有很多优良的特性,我们会在相关章节专门讲
作业
- 如何获取
matrix(1:9, nrow = 3)上对角元? 对角元?
- 对数据框,思考
df["x"],df[["x"]],df$x三者的区别? - 如果
x是一个矩阵,请问x[] <- 0和x <- 0有什么区别? - 不添加参数
na.rm = TRUE的前提下,用sum()计算向量x的元素之和
x <- c(3, 5, NA, 2, NA)提示:
- 使用
is.na(x)检查向量元素是否为缺失值,并保存为新的对象x_missing - 将所有缺失值赋值为0
- 然后
sum()计算
- 找出
x向量中的偶数
x <- 1:10
xpacman::p_unload(pacman::p_loaded(), character.only = TRUE)