Anscombe 四重奏
可视化的重要性
应用篇在可视化章节,我们提到 Anscombe’s quartet这个数据集,
?datasets::anscombe在其官方文档,我们可看到它是这样描述的:
Four x-y datasets which have the same traditional statistical properties (mean, variance, correlation, regression line, etc.), yet are quite different.
d <- datasets::anscombe
head(d)探索anscombe
library(tidyverse)本节课的内容,就是用tidyverse的方法去探索下这个数据集:
- 规整数据
- 分组统计
- 建模
- 可视化
规整数据
我们再看看数据
head(d)实际上,这是四组(x1, y1), (x2, y2), (x3, y3), (x4, y4)。那要怎么样规整数据, 或者说怎么样把数据弄成tidy呢。这里有个技巧,你可以想象,数据能ggplot()可视化的基本上就是tidy的。
d %>%
ggplot(aes(x = x, y = y)) +
geom_point() +
facet_wrap(~set)那么,我们希望我们的数据是这样的格式
| set | x | y |
|---|---|---|
| 1 | 10 | 8.04 |
| 1 | 8 | 6.95 |
| ... | ||
| 2 | 10 | 9.14 |
| 2 | 8 | 8.14 |
| ... |
小小的回顾
我们之前讲过,数据变形中,宽表格变成长表格, 需要用到tidyr::pivot_longer()函数 !图片
比如
dt <- tibble(id = c("a", "b"), x_1 = 1:2, x_2 = 3:4, y_1 = 5:6, y_2 = 8:9)
dt
dt %>% pivot_longer(-id,
names_to = "name",
values_to = "vaules"
)有时候,我们不想要下划线后面的编号,只想保留前面的第一个字母
dt %>% pivot_longer(
cols = -id,
names_to = "name",
names_pattern = "(.)_.",
values_to = "vaules"
)有时候人的需求是多样的,比如不想要前面的第一个字母,只要下划线后面的编号
dt %>% pivot_longer(
cols = -id,
names_to = "name",
names_pattern = "._(.)",
values_to = "vaules"
)有时候我们都想要呢?
dt %>% pivot_longer(
cols = -id,
names_to = c("name", "group"),
names_pattern = "(.)_(.)",
values_to = "vaules"
)有时候,我们希望"x", "y"保留在列名,那么匹配出来的第一个字母,就不能给"name",而是传给特殊的符号".value",它会收集匹配出来的字符,然后放在列名中
dt %>% pivot_longer(
cols = -id,
names_to = c(".value", "group"),
names_pattern = "(.)_(.)",
values_to = "vaules"
)是不是觉得很强大?
回到案例
具体来说,我们希望 x1 按照指定的正则表达式分成了两个部分 x和 1,那么1放在set下,而 x 传给了.value 当作变型后的列名.
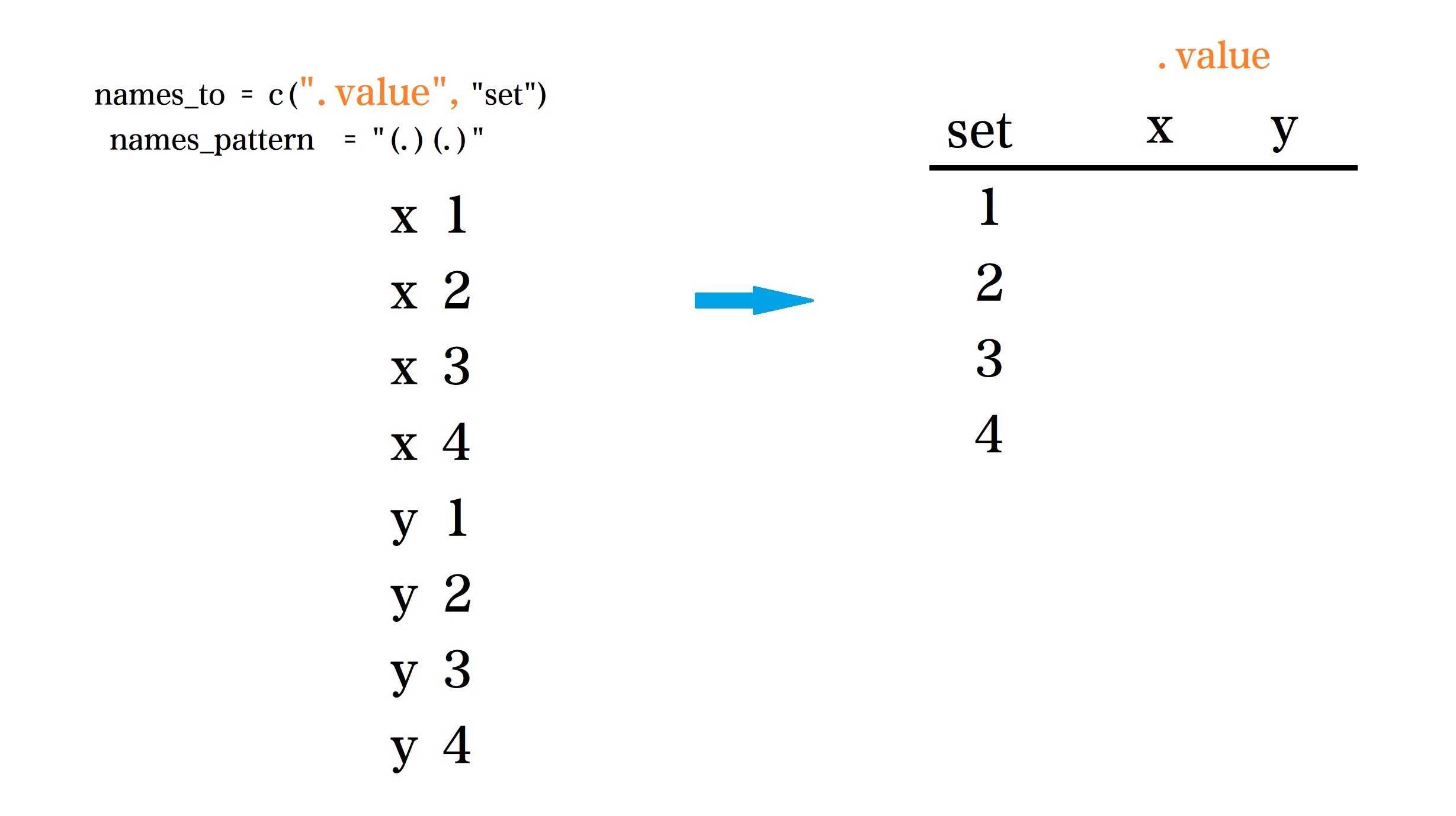
那么和上面的情况一样,使用tidyr::pivot_longer()函数
tidy_d <- d %>%
pivot_longer(
cols = everything(),
names_to = c(".value", "set"),
names_pattern = "(.)(.)"
)
tidy_d再啰嗦下参数的含义:
cols = everything()表示选择所有列names_to = c(".value", "set")希望变型后的列名是c(".value", "set"), 这里".value"是个特殊的符号,代表着names_pattern匹配过来的值,一般情况下,是多个值,如果传给".value"的"x, y, z",那么列名就会变成c("x", "y", "z", "set")names_pattern = "(.)(.)"将变换前的列名按照指定的正则表达式匹配,并且传递给names_to的对应的参数,比如这里第一个(.)传递给.value;第二个(.)传递给set.
统计
数据规整了,统计就很简单了
tidy_d_summary <- tidy_d %>%
group_by(set) %>%
summarise(across(
.cols = everything(),
.fns = lst(mean, sd, var),
.names = "{col}_{fn}"
))
tidy_d_summary建模
具体参考相关章节整理的四种方法
tidy_d %>%
group_nest(set) %>%
mutate(
fit = map(data, ~ lm(y ~ x, data = .x)),
tidy = map(fit, broom::tidy),
glance = map(fit, broom::glance)
) %>%
unnest(tidy)感觉大家更喜欢这种
tidy_d %>%
group_by(set) %>%
group_modify(
~ broom::tidy(lm(y ~ x, data = .))
)tidy_d %>%
group_by(set) %>%
summarise(
broom::tidy(lm(y ~ x, data = cur_data()))
)可视化看看
tidy_d %>%
ggplot(aes(x = x, y = y, colour = set)) +
geom_point() +
geom_smooth(method = "lm", se = FALSE) +
theme(legend.position = "none") +
facet_wrap(~set)# remove the objects
# rm(list=ls())
rm(d, dt, tidy_d, tidy_d_summary)pacman::p_unload(pacman::p_loaded(), character.only = TRUE)